01从“带宽无限”到“带宽受限”——理论与现实的落差
理论上,只要带宽一定,网络吞吐就不该受时延影响;长管道只是“截面积”变大,但数据包依旧能“挤”满整条链路。然而,把这条理论拿到实验室里用 TCP 一验,结果往往让人大跌眼镜:单条 TCP 连接在长肥管道里很难跑到额定带宽。
下面这张拓扑图,就是验证这一矛盾的起点:
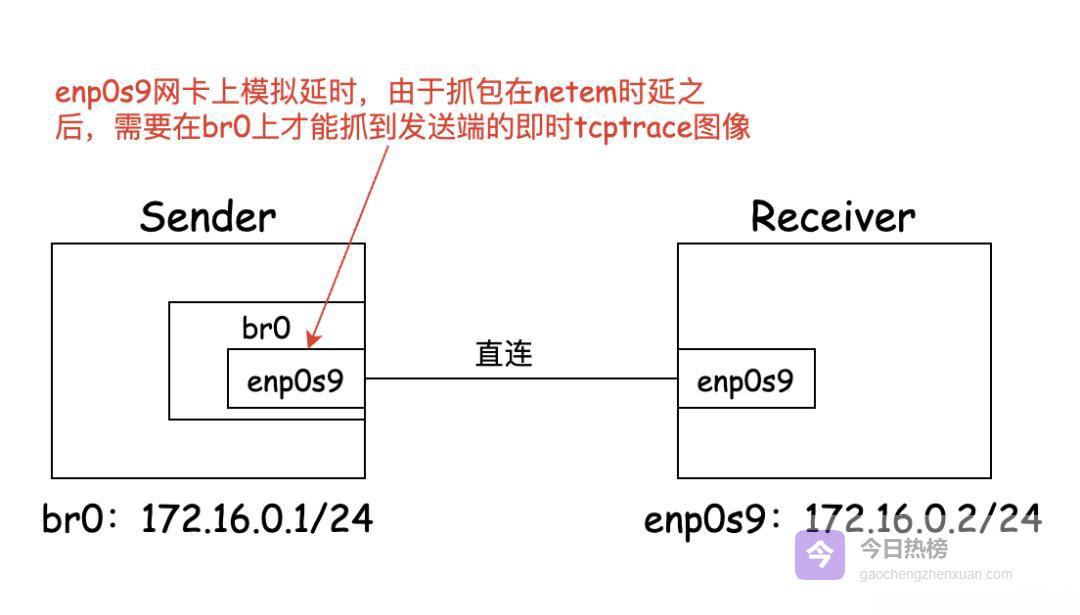
02裸带宽实测:1 Gb/s 直连链路轻松跑满
先让接收端(172.16.0.2)跑 iperf -s,发送端执行:
```
iperf -c 172.16.0.2 -i 1 -P 1 -t 2
```
输出显示:
```
[3] 1.0-2.0 sec 119 MBytes 996 Mbits/sec
[3] 2.0-3.0 sec 248 MBytes 1.04 Gbits/sec
```
直连链路轻松达到 1 Gb/s,基准测试完成。
03模拟长肥管道:RTT 100 ms,带宽瞬间掉队
在发送端插入 netem 延迟,单程 100 ms,再跑 iperf:
```
tc qdisc add dev enp0s9 root netem delay 100ms limit 50ms
```
结果惨不忍睹:
```
[3] 1.0-2.0 sec 11.1 MBytes 18.3 Mbits/sec
```
带宽只剩理论值的约 2%,与“带宽只与截面积有关”的推论大相径庭。
04三大“拦路虎”——单条 TCP 填不满长肥管道的真凶
为了找出症结,把问题拆成三条“必要条件”:
接收端窗口必须≥BDP
发送端缓冲区必须≥BDP
链路不能存在排队拥塞
4.1 【 BDP 到底有多大? 】以 1 Gb/s、100 ms 为例,BDP≈13 MB,换算成数据包约为 8947 个 1500 Byte 的 IP 包。
先给接收端开“后门”:
```bash
net.core.rmem_max=13420500
net.ipv4.tcp_rmem='4096 873800 13420500'
```
再让 iperf 在启动时指定窗口:
```
iperf -s -w 15m
```
服务器端显示:
```
TCP window size: 25.6 MByte (WARNING: requested 14.3 MByte)
```
接收窗口已足够大,不会成为瓶颈。
4.2 【 发送端缓冲区同样安排到位: 】```bash
net.core.wmem_max=13420500
net.ipv4.tcp_wmem='4096 873800 13420500'
```
发送端缓冲也足够,接下来只需让窗口爬升到 BDP。
4.3 【 长肥管道的“慢增窗”机制——Reno 的尴尬表现 】Reno 采用“锯齿状”探窗:每 RTT 只增加一个包,每秒最多探 10 个包。按这个速率,从零爬到 BDP≈8947 个包需要十几分钟。期间哪怕一次偶然丢包,窗口立刻减半,于是进度表又被清零。最终实测:
窗口稳定在 8980 左右(与理论 BDP 一致)
带宽稳定在约 955 Mbit/s(理论值的约 95%)
日志显示:
```plaintext
RTT:104118 curr cwnd:8980 curr inflight:8949
RTT:105555 curr cwnd:8980 curr inflight:8828
...
```
窗口不再增长,带宽也“止步”。问题看似出在“增窗太慢”,实则另有隐情。
05“噪声丢包”——看不见的杀手锏
独享链路上运行 ping -f,也能测到微小丢包:
```bash
ping -f 172.16.0.2 | grep -c 'lost' = 7 packets lost (6.8% loss)
```
这些丢包肉眼几乎不可见,却足以让 Reno 把窗口减半。当带宽利用率提升,噪声丢包概率同步上升;一旦触发丢包,窗口便进入“慢爬升—减半—再爬升”的死循环,于是带宽被牢牢锁死。即使把拥塞窗口硬撑到 BDP,只要噪声继续,“假性拥塞”就会让带宽跌回低谷。这也是为什么实测中即使窗口达标,带宽依旧只有理论值约 10% 的根本原因。
06把噪声“屏蔽”掉——实验级“作弊”验证 Reno 能力上限
用 SystemTap 写脚本,在内核层拦截 tcp\_reno\_ssthresh 与 tcp\_ack,把所有丢包事件强行“忽略”,再次跑 iperf:
```bash
iperf -c 172.16.0.2 -i 1 -P 1 -t 5 # 全局屏蔽乘性减窗
```
结果:5 s 内轻松跑到 1.12 Gb/s(BDP≈96%),证明 Reno 的“理论天花板”其实并不低,只是噪声丢包拖了后腿。但现实场景中我们无法如此“作弊”,任何对协议栈的修改都可能带来新的问题。于是回到原点——如何区分“噪声”与“拥塞”?BBR 给出了答案。
07BBR 的“捷径”——用测量代替猜测
切换到 BBR 后,同样的测试只需短短几秒:
```bash
iperf -c 172.16.0.2 -i 1 -P 1 -t 5 # 使用 BBR congestion control
```
输出:
```plaintext
[3] 3.0-4.0 sec 128 MBytes 1.08 Gbits/sec (一次测量即填满 BDP)
```
BBR 不依赖丢包来判定拥塞,而是直接估算可用带宽与 RTT,直接计算发包速率,绕开了噪声丢包的陷阱。可见,想要“快速填满长肥管道”,换算法是最直接且有效的手段。然而问题并未完全解决——公平性仍是一道坎。
08公平性与效率的取舍——BBR 的短板与历史根源
AIMD(加法增量乘法减量)算法背后有成熟的数学收敛模型:Reno 与 CUBIC 都可证明收敛到公平状态;而 BBR 在数学上无法保证公平性。下图直观展示了 AIMD 的收敛能力:
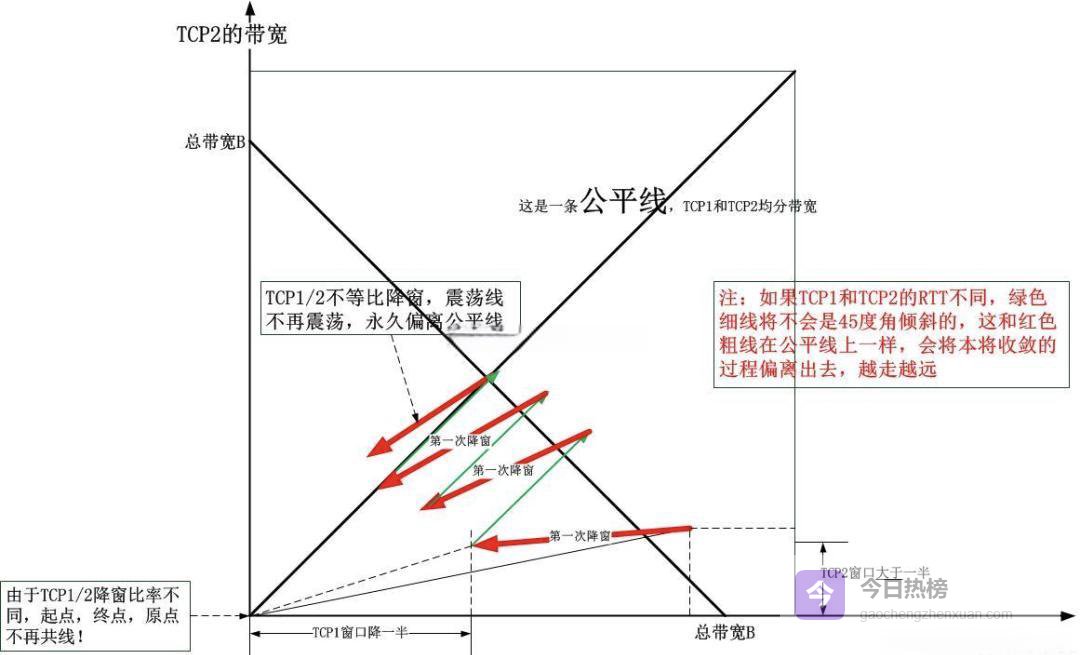
当网络出现多流竞争时,BBR 流可能持续霸占高带宽,而 Reno 流则快速让出资源,前者效率高却可能不公平,后者公平却效率低。历史背景是:TCP Reno 的诞生本就不是为了“跑得快”,而是为了在拥塞爆发时快速收敛、保证公平。如今我们要求它兼顾效率,本质上是让它同时扮演“裁判”与“运动员”。若想回到“无拥塞控制”时代的狂飙突进?只需关闭所有 TCP 控制即可——但代价是网络乱成一锅粥。于是回到现实:公共网络里长肥管道的随机噪声与真实拥塞交织,单流想持续跑高吞吐几乎是个奢望。那么如何在复杂网络里提升效率?答案只有两个字:拆分。把长肥管道切成短瘦段,让每段独立运行拥塞控制,即可绕过“长肥”带来的天然劣势。SDWAN 提供两种思路:TCP Proxy 或 TCP Tunnel。实验如下:### 把长肥管道切成两段——用隧道验证“分而治之”的效果#### 环境搭建继续沿用上面的拓扑,但增加两段隧道:S→T1→T2→D 每段隧道 RTT≈5 ms(本地回环),总路径≈5×2=10 ms(模拟短路径)。拓扑图如下: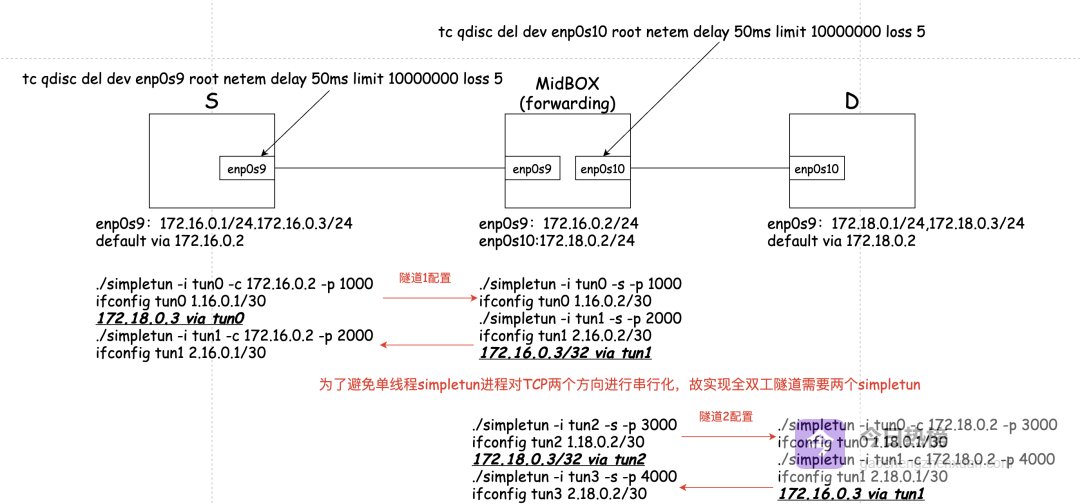 测试 Case:① 直接跑 S→D 长肥管道(Case1)② 先跑 S→T1→T2→D(Case2)测试结果对比一目了然:Case1(长肥):最高 699 Kbit/sCase2(两段短隧道):最高 2.14 Mbit/s(约提升 3 倍)RTT 从 ≈2 s → ≈5×2=10 ms 后,丢包感知、恢复速度都呈指数级提升;长肥管道被拆成若干短段后,每段独立运行拥塞控制,不再需要全局一致的探窗策略。#### 多段网络里的新玩法——细粒度策略定义当广域网由多个 Overlay 段组成时,每段可独立配置拥塞控制算法、带宽预留、优先级甚至 QoS 服务链;SDWAN 的动态路径选择与策略引擎把“分而治之”落到实处。细粒度策略 + 多段独立探窗 = 长肥管道也能高效跑满。## 结语从本文可以看到,TCP 在长肥管道里跑不满并不是协议设计缺陷,而是“长”与“肥”天然带来的增窗慢、丢包难恢复、噪声干扰三大难题;Reno 通过 AIMD 能收敛到公平却牺牲效率;BBR 用测量替代猜测效率高却难保证公平;最终解法只能是——把长肥管道切成若干短段,让每段独立运行最合适的拥塞控制策略。当分而治之成为现实,“长肥”就不再是性能瓶颈;而 SDWAN 则把这一愿景落到了可部署的网络层面。
测试 Case:① 直接跑 S→D 长肥管道(Case1)② 先跑 S→T1→T2→D(Case2)测试结果对比一目了然:Case1(长肥):最高 699 Kbit/sCase2(两段短隧道):最高 2.14 Mbit/s(约提升 3 倍)RTT 从 ≈2 s → ≈5×2=10 ms 后,丢包感知、恢复速度都呈指数级提升;长肥管道被拆成若干短段后,每段独立运行拥塞控制,不再需要全局一致的探窗策略。#### 多段网络里的新玩法——细粒度策略定义当广域网由多个 Overlay 段组成时,每段可独立配置拥塞控制算法、带宽预留、优先级甚至 QoS 服务链;SDWAN 的动态路径选择与策略引擎把“分而治之”落到实处。细粒度策略 + 多段独立探窗 = 长肥管道也能高效跑满。## 结语从本文可以看到,TCP 在长肥管道里跑不满并不是协议设计缺陷,而是“长”与“肥”天然带来的增窗慢、丢包难恢复、噪声干扰三大难题;Reno 通过 AIMD 能收敛到公平却牺牲效率;BBR 用测量替代猜测效率高却难保证公平;最终解法只能是——把长肥管道切成若干短段,让每段独立运行最合适的拥塞控制策略。当分而治之成为现实,“长肥”就不再是性能瓶颈;而 SDWAN 则把这一愿景落到了可部署的网络层面。
原创文章,作者:马超,如若转载,请注明出处:http://www.gaochengzhenxuan.com/rebang/20331.html

